آموزش زبان برنامهنویسی Rust – قسمت۱۲- در اعماق Struct

در جلسات قبلی هم با شیوهی تعریف یک struct آشنا شدیم و هم تعریف کردن و استفاده از method ها و associated function ها را یادگرفتیم. الان زمان این است که چند مبحث باقیمانده را هم درمورد struct ها با هم یادبگیریم تا بتوانیم بگوییم که همهی چیزهایی که مستقیماً به struct ها مرتبط اند را میدانیم. آمادهای؟ پس با هم شروع میکنیم.
فهرست مطالب
به ارث بردن مقادیر تعریف نشده از یک struct دیگر
فرضکنید که مثلاً ۱۰ نمونه از یک struct میخواهید بسازید که تنها در یک فیلد با هم اختلاف دارند. خب فرضکنید که هر struct خودش ۱۵تا فیلد داشته باشد. میخواهید به خاطر همان یک فیلدی که با بقیه فرق دارد،۹ مقدار مشابه دیگر را تکرار کنید؟ یعنی به خاطر ۱۰ دادهی متفاوت ۱۴۰ تا دادهی شبیه به هم را هی تکرار کنید؟
این کار زمان خیلی زیادی را از آدم میگیرد. به علاوه به خاطر افزونگی دادهای که پیش میآید (data redundency) نگهداری کد بسیار سخت میشود.
یک راه حل دیگر که ممکن است به ذهن آدم برسد این است که یک تابع بنویسد که فقط مقدار همان یک فیلد متغیّر را بگیرد و struct کامل را به عنوان خروجی بدهد.
مشکل این راه حل هم این است که وقتی تعداد این حالات در برنامه زیاد شد، یعنی struct هایی که فقط یک مقدار متفاوت دارند زیاد شدند، تعداد این توابع هم زیاد میشود. اینطوری نگهداری این توابع سخت میشود.
به علاوه تغییردادن کد هم پیچیده خواهد شد.
حالا راه حل Rust برای این مشکل چیست؟
فرضکنید که یک struct داریم که ۵ مقدار عددی مختلف دارد. از val1 تا val5. حالا ما میخواهیم دو تا نمونه از این struct بسازیم که فقط مقدار val5 بین آنها متفاوت است. اوّل کد را ببینید تا با هم خط به خطش را بررسی کنیم:
#[derive(Debug)]
struct TestStruct {
val1: i32,
val2: u8,
val3: i64,
val4: f64,
val5: u16
}
fn main() {
let struct1 = TestStruct {
val1: -1238,
val2: 5,
val3: -6464564564,
val4: 1234.5678,
val5: 15
};
let struct2 = TestStruct {val5: 236, ..struct1};
println!("struct1: {:#?}", struct1);
println!("struct2: {:#?}", struct2);
}
ما اوّل ساختار TestStruct را تعریف میکنیم. سپس داخل تابع main، ابتدا struct1 را تعریف میکنیم و ۵ مقدار آن را برایش مشخّص میکنیم.
حالا نوبت تعریف نمونهی دوم از این struct است. متغیّر struct2 را تعریف میکنیم و مقدار val5 را که با متغیّر قبلی متفاوت است مینویسیم.
برای اینکه به Rust بگوییم میخواهیم برای مقادیر بقیهی فیلدها از فیلدهای struct1 استفاده کنیم، باید از سینتکس خاصی استفاده میکنیم.
پس از مقداردهی فیلدهای غیر مشابه، ابتدا .. میگذاریم و سپس اسم متغیّری را که میخواهیم از مقادیر آن برای پرکردن فیلدهای باقیمانده استفاده کنیم میآوریم.
خب حالا ببینیم نتیجهی کامپایل و اجرای این برنامه چه خواهد بود.
struct1: TestStruct {
val1: -1238,
val2: 5,
val3: -6464564564,
val4: 1234.5678,
val5: 15
}
struct2: TestStruct {
val1: -1238,
val2: 5,
val3: -6464564564,
val4: 1234.5678,
val5: 236
}
مشکل ارثبری مقادیر قبلی با مالکیّت
بیایید فرضکنیم ما دو تا دانشجو داریم که فقط شمارهی دانشجویی آنها با هم متفاوت است (مثلاً دو نفر همنام که دقیقاً درسهای مشابهی را پاس کرده اند). میخواهیم این کار را با syntax جدیدی که یادگرفتیم انجام بدهیم:
fn main() {
let courses = [Course {name: String::from("درس۱"), passed: false},
Course {name: String::from("درس۲"), passed: false},
Course {name: String::from("درس۳"), passed: false}];
let student1 = Student {
name: String::from("اصغر اکبرزاده اصل"),
id: 9796959493,
courses
};
let student2 = Student {id: 9899969594, ..student1};
println!("student1: {:#?}", student1);
println!("student2: {:#?}", student2);
}
خب حالا یک نفش عمیق بکشید و برنامه را کامپایل کنید:
error[E0382]: use of partially moved value: `student1`
--> src/main.rs:37:33
|
35 | let student2 = Student {id: 9899969594, ..student1};
| -------- value moved here
36 |
37 | println!("student1: {:#?}", student1);
| ^^^^^^^^ value used here after move
|
= note: move occurs because `student1.name` has type `std::string::String`, which does not implement the `Copy` trait
اگر هنوز مبحث مالکیّت را به خاطر داشته باشید، حتماً به خاطر دارید که دادههایی مثل String کپی نمیشوند، بلکه مالکیّتشان منتقل (move) میشود.
در struct قبلی به چنین مشکلاتی نمیخوردیم. چون دادههای عددی سادهتر از آن هستند که لازم باشد مالکیّتشان جابهجا شود، به جای آن خود مقدار کپی میشود. به همین خاطر میتوانیم نمونهی جدیدمان از struct را با کپیکردن مقادیر struct قبلی بسازیم.
ما در struct های Student و Course دادههایی از نوع String داریم. به علاوه در Student آرایهای از Course ها داریم که برای این نوع داده (Course) هم رفتار کپی تعریف نشده است.
چطوری میتوانیم این مشکل را برطرف کنیم؟
#[derive(Debug, Clone)]
struct Student {
name: String,
id: u32,
courses: [Course; 3]
}
#[derive(Debug, Clone)]
struct Course {
name: String,
passed: bool
}
همانطوری که میبینید ما از trait جدیدی به نام clone استفاده کردهایم.
نکته: وقتی میخواهیم از چندین trait استفاده کنیم، میتوانیم تمام آنها را درون پرانتز derive قرار بدهیم تا کد کمتری نوشته باشیم. امّا میتوان از چندین derive مختلف برای این کار استفاده کرد.
امّا چرا این کار را میکنیم؟
ویژگی clone چیست؟
trait یا ویژگی ها را بعداً به شکل کامل بررسی میکنیم. اینجا فقط میخواهیم به صورت کلّی ببینیم که clone کردن در Rust یعنی چه.
در زبان Rust برخی type ها را میتوان به صورت ضمنی کپیکرد. یعنی وقتی که آنها را به متغیّری assign میکنیم یا به تابعی پاس میدهیم، بدون اینکه مشکلی پیش بیاید خود کامپایلر میتواند آنها را کپی کند.
این نوعدادههای ساده نه به اختصاص فضا در heap احتیاج دارند و نه به finalizer ها (بعداً میبینیم که چی هستند. فعلاً همان Drop را که در قسمتهای قبلی دیدیم در نظر بگیرد).
برای بقیهی نوعدادهها که انجام این کار ایمن نیست باید از clone استفاده کنیم.
وقتی از Clone استفاده میکنیم تمامی کارهای پیچیدهای که برای کپیکردن دقیق مقدار داده نیاز است توسّط خود حضرت Clone انجام میشود و ما لازم نیست نگران چیزی باشیم.
وقتی میخواهیم یک struct را clone کنیم، علاوه بر اضافهکردن ویژگی (trait) Clone، باید هرجایی که میخواهیم clone کردن رخ بدهد متد clone را روی struct فراخوانی کنیم.
حالا ببینیم با این توضیحات شکل کلّی برنامه چه میشود:
#[derive(Debug, Clone)]
struct Student {
name: String,
id: u32,
courses: [Course; 3]
}
#[derive(Debug, Clone)]
struct Course {
name: String,
passed: bool
}
fn main() {
let courses = [Course {name: String::from("درس۱"), passed: false},
Course {name: String::from("درس۲"), passed: false},
Course {name: String::from("درس۳"), passed: false}];
let student1 = Student {
name: String::from("اصغر اکبرزاده اصل"),
id: 97959493,
courses
};
let student2 = Student {id: 98999694, ..student1.clone()}; // Changed line
println!("student1: {:#?}", student1);
println!("student2: {:#?}", student2);
}
همانطوری که میبینید این بار به جای اینکه موقع تعریف کردن student2 از خود student1 استفاده کنیم، از مقدار clone شدهی آن استفاده میکنیم.
یعنی عملاً یک مقدار دقیقاً مشابه student1 میسازیم و از آن برای مقداردهی استفاده میکنیم. اینطوری مالکیّت مقدار clone شده منتقل میشود، نه خود student1.
حالا میتوانیم این برنامه را بدون درد و خونریزی کامپایل و اجرا کنیم:
student1: Student {
name: "اصغر اکبرزاده اصل",
id: 97959493,
courses: [
Course {
name: "درس۱",
passed: false
},
Course {
name: "درس۲",
passed: false
},
Course {
name: "درس۳",
passed: false
}
]
}
student2: Student {
name: "اصغر اکبرزاده اصل",
id: 98999694,
courses: [
Course {
name: "درس۱",
passed: false
},
Course {
name: "درس۲",
passed: false
},
Course {
name: "درس۳",
passed: false
}
]
}
ساختارهای شبه Tuple
یادتان است که tupleها چه چیزی بودند؟ (اگر نیست روی این نوشته کلیک کنید تا یادتان بیاید.) گفتیم که مهمترین ویژگی struct ها این است که برخلاف tuple ها مقادیرشان نام دارند و به جای اینکه بخواهیم ترتیب دادهها را حفظ کنیم، میتوانیم به آنها با استفاده از key ها دسترسی داشته باشیم. حالا ما میخواهیم که یک struct تعریف کنیم که شبیه به تاپل باشد. یعنی دادههایی که درونش قرار دارند اسم نداشته باشند:
#[derive(Debug)]
struct TupleLike (u8, u8, u8);
fn main() {
let mut tuple_like = TupleLike(10, 11, 13);
println!("tuple like value: {:?}", tuple_like);
tuple_like.0 = 18;
println!("tuple like value: {:?}", tuple_like);
}
همانطوری که میبینید، برای تعریف یک tuple like struct برخلاف تعریف struct، ما تنها مقابل نام struct و درون پرانتزها به ترتیب نوع دادههایی که قرار است ذخیره بشوند را مینویسیم. در اینجا دیگر خبری از زوجهای key:value نیست.
برای دسترسی به یک دادهی خاص هم کافی است که مقابل نام نمونهی ساخته شده از struct، اندیس دادهای که قرار است تغییرکند را پس از علامت نقطه بنویسیم.
حالا برنامه را کامپایل و اجرا میکنیم تا ببینیم نتیجه چه میشود:
tuple like value: TupleLike(10, 11, 13) tuple like value: TupleLike(18, 11, 13)
چرا باید از tuple like struct ها استفاده کنیم؟
ما زمانی از tuple like struct ها استفاده میکنیم که به عملکردی مشابه tuple ها احتیاج داریم، امّا لازم است که این تاپلها type های متمایزی داشته باشند. مثلاً میخواهیم مطمئن بشویم که درون برنامه، تاپل چهارتاییای که مقدار رنگ یک پیکسل را در فرمت CMYK نگهداری میکند با تاپل چهارتاییای که بخشهای مختلف یک ip ورژن ۴ را نگهداری میکند متمایز اند.
#[derive(Debug)]
struct CMYK (u8, u8, u8, u8);
#[derive(Debug)]
struct IPv4 (u8, u8, u8, u8);
fn main() {
let red = CMYK(0, 1, 1, 0);
let local_ip = IPv4(127, 0, 0, 1);
println!("red color {:?} and local ip {:?}. These values have different types.", red, local_ip);
}
نتیجهاش هم میشود این:
red color CMYK(0, 1, 1, 0) and local ip IPv4(127, 0, 0, 1). These values have different types.
وقتی که برنامه بزرگ میشود و تعداد tupleها زیاد، با جداسازی type احتمال خطا خیلی کمتر میشود. به علاوه ما میتوانیم به struct ها عملکردهای مرتبط را هم سنجاق کنیم. کاری که برای tuple ها نمیشد انجام داد.
نوعدادهی Unit
به () ،unit یا nil هم میگویند. Typeی که تنها یک مقدار دارد و آن هم همان () است. از unit وقتی استفاده میشود که مقدار معنادار دیگری برای return کردن وجود ندارد.
در حقیقت وقتی در تابعی هیچ چیزی را return نمیکنیم، داریم () را برمیگردانیم.
به جز توابعی که چیزی برنمیگردانند، از () در زمانهایی استفاده میکنیم که نوع دادهای که با آن کار میکنیم برایمان اهمّیّتی ندارد.
ساختارهای شبه Unit
ما میتوانیم structها را طوری تعریف کنیم که مثل یک unit عمل کنند. یعنی structهایی بسازیم که هیچ فیلدی ندارند. از Unit like structs زمانی استفاده میکنیم که میخواهیم یک ویژگی (trait) را برای یک type تعریفکنیم، امّا نمیخواهیم دادهای را در آن type ذخیره کنیم. بعداً در بخشهای مربوط به توضیح trait ها با مثالهای مختلف این موضوع را بررسی میکنیم.
#[derive(Debug)]
struct UnitLikeStruct;
fn main() {
let my_unit = UnitLikeStruct;
let same_unit_as_my_unit = UnitLikeStruct {};
println!("my_unit: {:?}, same_unit_as_my_unit: {:?}", my_unit, same_unit_as_my_unit);
}
نتیجهی این برنامه میشود این:
my_unit: UnitLikeStruct, same_unit_as_my_unit: UnitLikeStruct
تعریف Recursive Type

یکی از مشکلات بزرگی که برنامهنویسها ممکن است به آن بخورند مسئلهی Recursive Typing است.
یعنی ما دو تا struct داشته باشیم که هرکدام یک فیلد از نوع دیگری دارند. اینطوری بهصورت چرخشی باید به اندازهی این یکی برای ساخت نمونهای از آن یکی فضا اختصاص داد و برعکس. یعنی به بینهایت حافظه نیاز خواهیم داشت.
بیایید با هم یک مثال را بررسی کنیم. فرضکنید که یک struct به نام Teacher به برنامهی اوّلیّه اضافه میکنیم:
#[derive(Debug, Clone)]
struct Course {
name: String,
passed: bool,
teacher: Teacher
}
#[derive(Debug)]
struct Teacher {
name: String,
course: Course
}
ما ساختار Teacher را اضافه کردیم که دو تا فیلد دارد. name که نام استاد را مشخّص میکند و course که ساختار درسی که این فرد استاد آن است را نگهداری میکند.
به علاوه ساختار Course را هم تغییر دادهایم تا در فیلد teacher ساختار مربوط به استاد درس را نگهداری کند.
خب حالا بیایید یک نمونه استاد و درس بسازیم:
fn main() {
let course: Course;
course = Course {
name: String::from("درس۱"),
passed: false,
teacher: Teacher {
name: Student::from("عین الله"),
course
}
};
}
شاید در نگاه اوّل مشکلی به نظر نرسد، امّا بیایید که برنامه را کامپایل کنیم:
error[E0072]: recursive type `Course` has infinite size
--> src/main.rs:9:1
|
9 | struct Course {
| ^^^^^^^^^^^^^ recursive type has infinite size
...
12 | teacher: Teacher
| ---------------- recursive without indirection
|
= help: insert indirection (e.g., a `Box`, `Rc`, or `&`) at some point to make `Course` representable
error[E0072]: recursive type `Teacher` has infinite size
--> src/main.rs:16:1
|
16 | struct Teacher {
| ^^^^^^^^^^^^^^ recursive type has infinite size
17 | name: String,
18 | course: Course
| -------------- recursive without indirection
|
= help: insert indirection (e.g., a `Box`, `Rc`, or `&`) at some point to make `Teacher` representable
کامپایلر به ما ۲ ارور مختلف نشان میدهد. یکی از ارورها میگوید که نوعدادهی بازگشتی Course فضای بینهایت احتیاج دارد. ارور دوم هم دقیقاً همین حرف را برای Teacher میزند. کامپایلر موقع کامپایل باید بداند که چقدر فضا برای هر متغیّر باید اختصاص بدهد. مشکل این است که کامپایلر نمیداند کی باید از حلقهی ایجاد شده برای اختصاص فضا خارج بشود. حلقهای که ایجاد میشود شبیه به شکل زیر است:
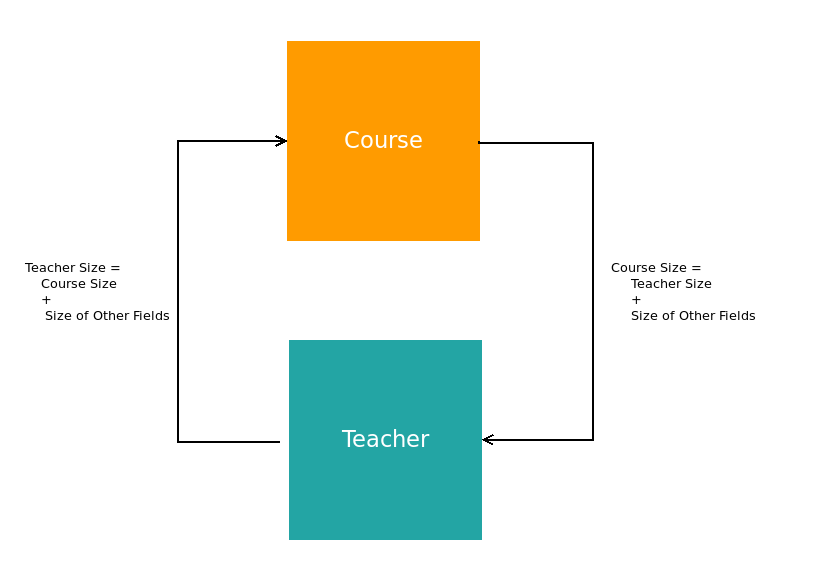
وقتی که کامپایلر میخواهد اندازهی Course را محاسبه کند به اندازهی Teacher نیاز دارد و هرگاه که بخواهد اندازهی Teacher را بفهمد به اندازهی Course نیاز دارد. اینطوری برای اینکه بخواهیم فقط همین برنامهی کوچکی که آن بالا نوشتیم را اجرا کنیم به بینهایت حافظه احتیاج داریم.
چطوری مشکل حافظهی بینهایت را در Recursive Type ها برطرف کنیم؟
اگر به پیام خطایی که بالاتر دیدیم دقّت کنید، میبینید که کامپایلر ۳ راه حل جلوی پای ما قرار داده است. در بخشهای بعدی هرکدام از این ۳ راه حل را با دقّت و به صورت کامل بررسی میکنیم. بحث هرکدام مفصّل است و برای بعضی باید مباحث دیگری را هم یادبگیریم. امّا خیلی وقتها ما واقعاً به ایجاد این حلقه احتیاج نداریم. یعنی معماری بد باعث شده است که چنین حلقهای به وجود بیاید. قبل از اینکه به سراغ هرکدام از آن ۳ راه حل بروید (البته الان که بلد نیستید. آن زمانی که یادگرفتیم 🙂 )، ابتدا یک بار دیگر معماری نرمافزارتان را بررسی کنید تا ببینید که آیا واقعاً به چنین کاری نیاز است یا نه.
خب تا اینجا تمامی چیزهایی که مستقیماً به struct ها مربوط میشدند را بررسی کردیم. الان که کار با struct ها را یادگرفتیم میتوانیم برنامههای کاربردیتری را با Rust پیادهسازی بکنیم. هنوز مفاهیمی باقیماندهاند که از آنها هم میتوان در struct استفاده کرد، امّا بعداً به صورت مجزا به آن بخشها خواهیم پرداخت.
چطوری به کدهای این قسمت دسترسی داشته باشم؟
یا حرفهای شو یا برنامهنویسی را رها کن.
چطور میشود در بازار کار خالی از نیروی سنیور ایران، بدون کمک دیگران و وقت تلفکردن خودت را تبدیل به یک نیروی باتجربه بکنی؟
پاسخ ساده است. باید حرفهای بشوی. چیزی که من در این کتاب به تو یاد خواهم داد.



سلام عالی بود کارتون حرف نداره فقط تنها ایرادش اینکه دیر به دیر میزارین
به هر حال منتظر ادامش هستیم ممنون ازتون