۶ دلیل برای اینکه هرگز از مقادیر Global استفاده نکنید

قرار است که روی یک پروژهی جدید کار کنی. فایلهای پروژه را باز میکنی و دنبال فایلی که به نظر باید آن را تغییر بدهی تا مشکلی که گزارش شده است را برطرفکنی میگردی.
فایل را باز میکنی و شروع به خواندن توابع میکنی. دادهها از جاهایی خوانده میشوند که توی این فایل نیستند. بدتر اینکه نتیجهی کار هم دارد در متغیّری ریخته میشود که اینجا نیست.
بیخیال این فایل میشوی و به سراغ نقطهی شروع برنامه میروی. تابع main را پیدا میکنی. چشمت به خط اوّل تابع میافتد و احساس میکنی که ضربان قلبت مدام بیشتر میشود.
InitGlobalVariables();
یک بار دیگر فایلهای پروژه را نگاه میکنی. دایرکتوری GlobalVariables را باز میکنی. به دهها فایلی که درونش قرار دارد نگاه میکنی. برای چندثانیه به صدها متغیّر Global درون هرکدام از فایلها فکر میکنی. کمکم درد درون سینهات متراکم میشود. چشمانت آرامآرام بسته میشوند. آخرین کلمات به سختی از لابهلای دندانهای کلیدشدهات بیرون میآیند: GLOBAL VARIABLE

فهرست مطالب
الان دارد چه اتّفاقی میافتد؟
این یک داستان کاملاً واقعی بود. امّا همیشه داستان به این ترسناکی نیست. گاهی فقط با ۱۰-۲۰ تا متغیّر Global در تمام کد سر و کار داریم. گاهی حتّی فقط یک مقدار Global در تمام برنامه وجود دارد.
بزرگترین مشکل وجود مقادیر Global در کد این است که خوانایی کد را از بین میبرند. در حالت عادی ما تمام چیزهایی که داریم، ورودیها و خروجیهای تابع به همراه متغیّرهایی که خودمان درون آن تعریف کردهایم است.
اگر هم داریم از زبانهای شئگرا استفاده میکنیم، به مجموعهی قبلی میتوان attribute های خود کلاس یا والدهایش را هم اضافه کرد. به هر حال همهچیز طبق یک نظم منطقی مشخّص است.
وقتی که ما میخواهیم مقداری که درون یک متغیّر ریخته میشود را عوضکنیم، به راحتی مشخّص میشود که این متغیّر کجا ساخته شده است و توسّط چه کسی دارد مقدار میگیرد.
امّا وقتی که پای متغیّرهای Global در میان باشد همهچیز فرق میکند.
متغیّر Global چیست؟
برای افرادی که نمیدانند و البته برای یادآوری به آنهایی که میدانند، بیایید یک بار تعریف متغیّر Global را مشخّص کنیم:
به متغیّری که در تمام برنامه در دسترس است، متغیّر جهانی یا Global میگویند.
خب حالا چرا متغیّر Global نظمی که گفتیم را بههممیزند و خوانایی کد را نابود میکند؟
متغیّر Global متعلّق به این scope کد نیست. پس ما باید بگردیم تا بفهمیم که کجا تعریف شده است. امّا این تنها مشکل نیست.
از آنجایی که متغیّرهای Global در تمام کد در دسترس هستند، پس هرکسی و در هرجایی میتوانید مقدار آنها را بخواند یا مقدارشان را عوض کند. این یعنی اینکه فهمیدن اینکه دقیقاً چه اتّفاقی دارد میافتد که مقدار این متغیّر خراب شده است بینهایت سخت است. چون ما باید تمام بخشها و component هایی را که ممکن است از این متغیّر استفاده کنند را از نو و بادقّت بخوانیم تا بفهمیم که مشکل ممکن است در کجا ایجاد شده باشد.
و خب خوانایی کمتر، یعنی کدی که تغییر و نگهداری آن سختتر است و امکان اشتباه در موقع کار با آن بیشتر.
مقادیر Global بیشتر یعنی نگهداری سختتر
گفتیم که نگهداری کدهایی که از مقادیر Global دارند استفاده میکنند سختتر است. امّا چقدر سختتر؟
نویسندگان این مقاله همین موضوع را بررسی کردهاند. آنها کدهای نرمافزارهای متنباز معروف زیر را در مدّت زمانهای مختلف بررسی کردهاند:
| نام برنامه | مدّتزمان بررسی (واحد زمان سال است) | تعداد نسخههای منتشرشده در زمان بررسی |
|---|---|---|
| temacs | ۱۴ | ۱۰ |
| cc1 | ۷ | ۲۹ |
| libbackend.a | ۷ | ۲۷ |
| libbackend.so.a | ۷ | ۱۱ |
| make | ۱۶ | ۱۸ |
| postgres | ۱۱ | ۱۰ |
| vim | ۸ | ۹ |
هدف بررسی این بوده است که ببینند که آیا میزان استفاده از مقادیر Global با کاهش امکان نگهداری کد رابطهای دارد یا نه.
میزان کاهش امکان نگهداری را هم با این ۲ معیار اندازهگیری کردهاند:
۱- فایلهایی که رفرنسهای بیشتری به مقادیر Global دارند بیشتر از فایلهایی که رفرنسهای کمتری به مقادیر Global در آنها وجود دارد تغییر میکنند.
۲- خطوط بیشتری از فایلهایی که رفرنسهای بیشتری به مقادیر Global دارند، هنگام ایجاد تغییر در برنامه عوض میشوند.
میزان وابستگی یا Coupling چیست؟
قبل از اینکه به نتایج آن مقاله بپردازیم، بیایید ببینیم که میزان وابستگی یا Coupling چیست؟
میزان وابستگی به میزان اتکای یک ماژول به سایر ماژولها گفته میشود. هدف ما در طرّاحی معماری این است که تا حد امکان میزان وابستگی بین ماژولها را کاهش بدهیم و میزان چسبندگی (Cohesion) بین اجزای هر ماژول را افزایش بدهیم.
یعنی اعضای ماژول با هم ارتباط زیادی داشته باشند، امّا ارتباط و اتّکای ماژولها به همدیگر تا حد امکان کم باشد. اینطوری ما اکثر اوقات برای تغییردادن یک بخش نیازی به تغییر دادن بخشهای دیگر پیدا نمیکنیم.
چرا وابستگی بیشتر نگهداری کد را سختتر میکند؟
خب بیایید برگردیم به همان مقالهای که به آن اشاره کردیم.
در نمودار زیر میتوانید میزان نسبت تغییرات را در طول زمان به میزان استفاده از مقادیر Global برای cc1 ببینید (LOC مخفف lines of code است. در هر نمودار یک خط مربوط به فایلهایی است که مجموعاً به ۵۰٪ مقادیر Global رفرنس دادهاند و دیگری مربوط به تمام فایلهای دارای رفرنس به مقادیر Global):
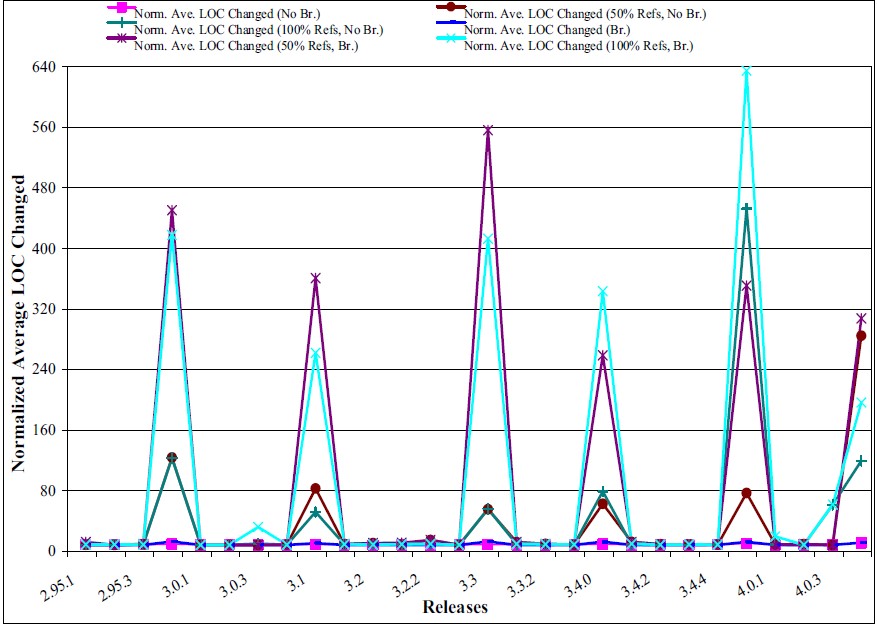
در نمودار پایینی هم همین اطّلاعات برای postgres آورده شده است: 
همانطوری که مشاهده میکنید میزان تغییرات برای بخشهایی که از مقادیر Global دارند استفاده میکنند بسیار بالاتر است.
دلیل این اتّفاق تا حدود زیادی واضح است. وقتی که مقادیری دارند بین بخشهای مختلف کد به اشتراک گذاشته میشوند، تغییر یک بخش با احتمال بالاتری باعث ایجاد تغییر در بخشهای دیگر میشوند.
یعنی تغییرات در کد به شکل یک آبشار بین فایلها، کلاسها و کامپوننتهای مختلف منتشر میشود.
مقادیر Global زیاد یعنی اینکه این کد را نمیتوان دوباره استفاده کرد
گفتیم که وجود مقادیر Global یعنی اینکه بخشهای مختلف کد به هم وابستهاند. حالا این قضیه چطوری استفادهی دوباره از کد را سخت میکند؟ بیایید با هم شکل زیر را ببینیم:

ما میخواهیم که از Module1 در یک جای دیگر استفاده کنیم. حالا این ماژول از طریق همین مقادیر Global به Module2 وابسته است. این زنجیرهی وابستگی تا ماژول شمارهی ۵ ادامه پیدا میکند.
این یعنی اینکه ما اگر بخواهیم از ماژول ۱ دوباره استفاده کنیم، ناچاریم که ۴ ماژول دیگر را هم همراه آن بیاوریم و اثرات ناخواستهی وجود آنها را هم بپذیریم.
خب حالا این مشکل تا چه حد جدی و مهم است؟
همهی ما کرنل لینوکس را به عنوان یکی از مهمترین نرمافزارهایی که بشر تا به امروز نوشته است قبول داریم. افرادی که روی کرنل کار میکنندبرنامهنویسهای واقعاً عالی محسوب میشوند. امّا همین عدم مدیریت استفاده از مقادیر Global برای کرنل مشکل ایجاد کرده است.
در این مقاله (که البته چندان جدید نیست) میزان و نوع استفاده از مقادیر Global در کرنل لینوکس بررسی شده است. اگر این مقاله را بخوانید میبینید که ۶۳٪ از مقادیر Global استفاده شده در کرنل، از ماژولهایی هستند که درون خود کرنل قرار ندارند. یعنی توسعهدهندگان کرنل لینوکس وابستگی زیادی به مقادیری دارند که درون ماژولهایی نگهداری میشوند که اصلاً توسعهی آنها دست این افراد نیست.
یعنی اگر فردا یکی از این ماژولها تغییری بکند، تمام بخشهایی از کرنل که دارند از آن استفاده میکنند دچار مشکل میشوند. این خودش باعث کندی توسعه و ایجاد مشکلات ایمنی و امنیّتی در کرنل میشود.
حالا این اتّفاق چه تأثیری در استفادهی دوباره یا reusability کد دارد؟
در مقالهی بعدی همان نویسنده این موضوع بررسی شده است. برای این کار امکان استفادهی مجدد دو سیستم عامل MkLinux و Darwin از کرنل Mach Kernel، Linux و FreeBSD مورد بررسی قرارگرفته است. نتیجهی این بررسی در جدول زیر آمده است:
| سیستم هدف | استفادهی مجدد از کرنل | تعداد کامپوننتهایی که مجدداً از آنها استفاده شده است | اندازهی کامپوننتهای مجدداً استفاده شده (KLOC) | تعداد خطوط تغییریافته (KLOC) |
|---|---|---|---|---|
| MkLinux | Linux | ۱۵۹۹ | ۷۴۱.۹۵۹ | ۳۳۲.۶۶۸ |
| MkLinux | Mach | ۴۵۹ | ۲۴۹.۲۶۸ | ۱۱۲.۹۸۷ |
| Darwin | FreeBSD | ۲۷۱ | ۱۷۹.۹۴۸ | ۱۷۸.۰۹۳ |
| Darwin | Mach | ۲۴۸ | ۱۲۳.۴۴۲ | ۹۱.۲۵۳ |
ولی برای اینکه میزان زحمت لازم برای استفادهی مجدد را بتوانیم تشخیص بدهیم باید ببینیم که چه تعداد کامپوننت جدید برای هرکدام از سیستمعاملهای Darwin و MkLinux نوشته شده است و هرکدام چند خط کد جدید لازم داشته اند. چیزی که در جدول زیر آمده است:
| سیستم هدف | تعداد کامپوننتهای جدید | اندازهی کامپوننتهای جدید (KLOC) |
|---|---|---|
| MkLinux | ۲.۷۲۴ | ۹۳۸.۱۳۲ |
| Darwin | ۱.۳۳۵ | ۴۴۱.۷۰۳ |
همانطوری که مشخّص است، استفادهی مجدد از FreeBSD و Mach زحمت کمتری خواهد داشت. ولی حالا این چه ربطی به میزان متغیّرهای Global دارد؟ در تصویر زیر جدول مربوط به میزان وابستگی حاصل از مقادیر Global آمده است:

لینوکس با بیشتری میزان وابستگی، کمترین قابلیّت استفادهی مجدد را دارد.
حتّی اگر به اندازهی توسعهدهندگان لینوکس هم برنامهنویسهای خوبی باشید، باز مقادیر Global برایتان دردسرساز خواهند شد.
این برنامه دیگر ایمن نیست
هنگامی که ما داریم از متغیّرهای Global استفاده میکنیم، دیگر برنامهی ما ایمن نیست. هرکسی ممکن است که در هرکجای برنامه مقدار متغیّر را تغییر بدهد. این باعث میشود که احتمال خطا بالا برود و باگهای مختلف در برنامه ایجاد شوند.
به شبهکد زیر نگاهکنید:
global int a = 0
Module1 {
function1 {
a += 10
}
}
Module2 {
fucntion1 {
a = 0
}
function2 {
a += 5
}
}
ما ۲ ماژول مختلف داریم با یک مقدار Global به نام a. ماژول اوّل یک تابع دارد که مقدار این متغیّر Global را با عدد ۱۰ جمع میکند.
ماژول دوم هم ۲ تابع دارد. اوّلی مقدار متغیّر Global را برابر ۰ قرار میدهد و دومی مقدار آن را با عدد ۵ جمع میکند.
خب حالا فرضکنید که شما دارید روی ماژول دوم کار میکنید. در یک جای این ماژول تابع اوّل فراخوانی میشود. پس شما انتظار دارید که مقدار متغیّر a برابر صفر شود. در یک جای دیگر از همین ماژول هم تابع دوم دارد فراخوانی میشود. از آنجایی که طبق منطق ماژول این فراخوانی بعد از فراخوانی تابع اوّل رخداده است، پس شما انتظار دارید که مقدار نهایی متغیّر a برابر با عدد ۵ شود.
امّا اگر در روند اجرای برنامهی اصلی که از هر دوی این ماژولها دارد استفاده میکند، تابع ماژول اوّل پیش از تابع دوم Module2 فراخوانی شود، شما اشتباه کردهاید و برنامهی شما رفتار اشتباهی از خود نشان میدهد.
بعضی از زبانها مثل Rust تلاش میکنند که با immutable کردن مقادیر و اجبار برنامهنویس به استفاده از سینتکس unsafe این مشکل را برطرف کنند، امّا هنوز در اکثر موارد این یک مشکل بالقوه است.
همزمانی ممنوع
مشکل بعدی مشکل استفاده از مقادیر Global در برنامههایی است که از مکانیزمهای همزمانی مثل thread استفاده میکنند.
عملکرد یک thread میتواند داده را به شکلی تغییر بدهد که عملکرد یک thread دیگر اشتباه شود. فراموش نکنید که مکانیزمهایی مثل mutex و… صرفاً میتوانند جلوی تغییر همزمان این مقادیر را بگیرند. امّا نمیتوانند درستی تغییرات ایجاد شده بر روی مقادیر Global را از نظر هر thread بررسی کنند. به همین خاطر همواره احتمال ایجاد خطا در منطق برنامه وجود دارد.
برنامهای که حافظه را میخورد
مسئلهی آخر با مقادیر Global این است که این مقادیر در تمام مدّت حیات برنامه درون حافظه باقی میمانند. به همین خاطر اگر شما مقادیر زیادی از حافظه را به عنوان مقادیر Global تعریف کنید، برنامههای دیگری که همزمان با برنامهی شما دارند روی سیستم کاربر اجرا میشوند ممکن است که با مشکل کمبود حافظه روبهرو شوند.
شما در حالت عادی وقتی یک شئ را میسازید یا حافظهای را allocate میکنید، پس از اتمام کار، حافظهای که به آن اختصاص یافته بود را آزاد میکنید. این باعث میشود که سیستم عامل بتواند آن حافظه را در اختیار باقی برنامهها قرار بدهد.
امّا مقادیر Global تا پایان عمر نرمافزار در حافظه خواهند بود و حافظهای که اشغال میکنند برای دیگران غیر قابل دسترس خواهد بود.
The form you have selected does not exist.
نتیجهگیری
درست است. گاهی هیچ راهی به جز استفاده از مقادیر Global وجود ندارد. ولی حقیقت این است که ما باید تمام تلاشمان را بکنیم که تا حد امکان از رخدادن چنین حالتی جلوگیری کنیم.
شاید در لحظهای که دارید برنامه را مینویسید به نظرتان وجود همین یک متغیّر Global چیز مهمی نباشد، امّا مشکلات وجود این مقادیر خیلی زود گریبان خودتان و بقیهی برنامهنویسهایی که قرار است روی این برنامه کار کنند را میگیرد.
یا حرفهای شو یا برنامهنویسی را رها کن.
چطور میشود در بازار کار خالی از نیروی سنیور ایران، بدون کمک دیگران و وقت تلفکردن خودت را تبدیل به یک نیروی باتجربه بکنی؟
پاسخ ساده است. باید حرفهای بشوی. چیزی که من در این کتاب به تو یاد خواهم داد.


